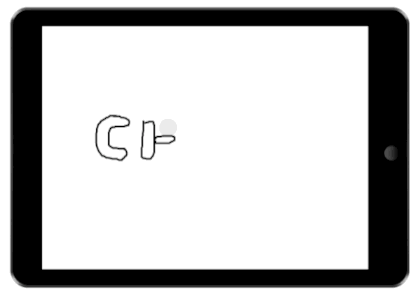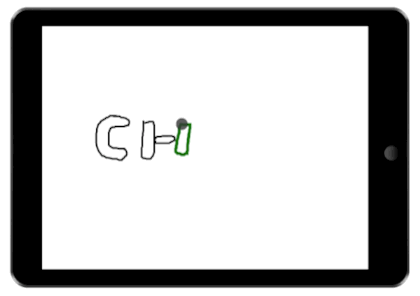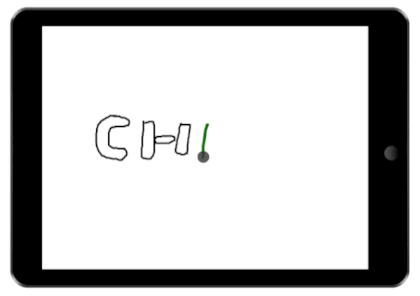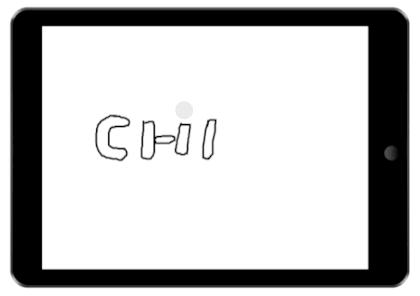An Architecture for Generating Interactive Feedback in Probabilistic User Interfaces
This paper is the third of three research papers published as part of my PhD thesis.
Increasingly natural, sensed, and touch-based input is being integrated into devices. Along the way, both custom and more general solutions have been developed for dealing with the uncertainty that is associated with these forms of input. However, it is difficult to provide dynamic, flexible, and continuous feedback about uncertainty using traditional interactive infrastructure. Our contribution is a general architecture with the goal of providing support for continual feedback about uncertainty.
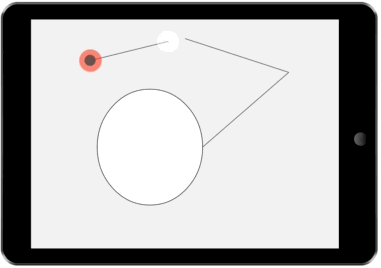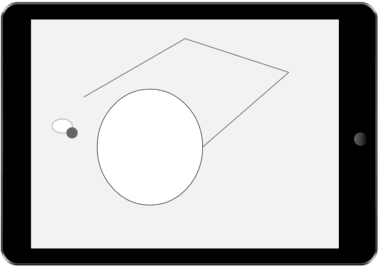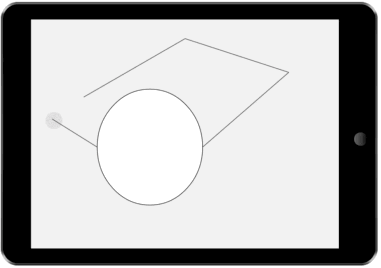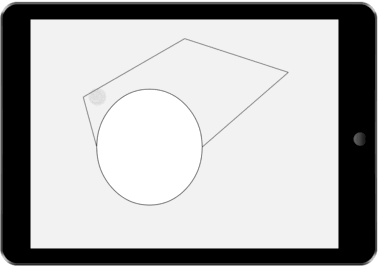
Our architecture tracks multiple interfaces – one for each plausible and differentiable sequence of input that the user may have intended. This paper presents a method for reducing the number of alternative interfaces and fusing possible interfaces into a single interface that both communicates uncertainty and allows for disambiguation.
Rather than tracking a single interface state (as is currently done in most UI toolkits), we keep track of several possible interfaces. Each possible interface represents a state that the interface might be in. The likelihood of each possible interface is updated based on user inputs and our knowledge of user behavior. Feedback to the user is rendered by first reducing the set of possible interfaces to a representative set, then fusing interface alternatives into a single interface, which is then rendered.
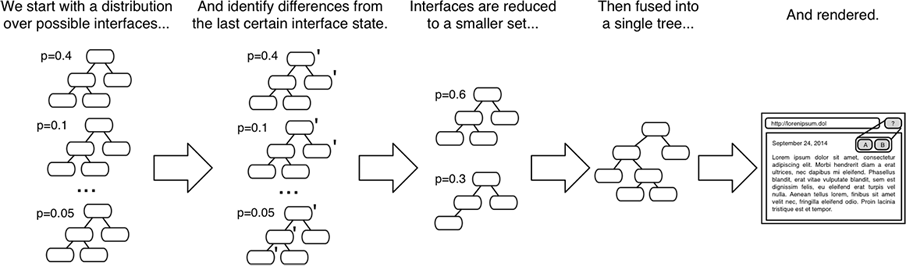
We demonstrate the value of our architecture through a collection of new and existing feedback techniques. The figures on the right show a few example interactions our architecture enables. In each demonstration, several possible interfaces are tracked. These possible interfaces are then fused into a single interface and presented to the user.